为什么写 panelforest
做临床研究、meta 分析或者 NMA 的人,森林图是绑定出图。R 里现有的工具不少——forestplot、forestploter、forester、meta::forest()——但用下来都多少有些不顺手:
- 很多包的 API 偏”配置式”,参数一多就变成巨长的函数调用,想调整布局得翻文档猜参数名
- 想要的面板组合经常不在预设里:比如左边文本、中间 CI、右边再来一列柱状图,基本要自己拼
- 分组行、汇总行、条纹、分隔线这些装饰性元素,每个包的处理方式都不一样
- 想给特定行换颜色、换形状,往往要改底层数据或者用很 hack 的方式
所以我写了 panelforest。
核心想法很简单:森林图本质上就是几列面板横向拼在一起,每列有自己的渲染逻辑。 那就不要把它当成一个”森林图函数”来设计,而是让用户自己声明”我要哪些列、每列长什么样”,剩下的事情交给引擎。
项目地址:https://github.com/lenardar/panelforest
长什么样
先看结果:
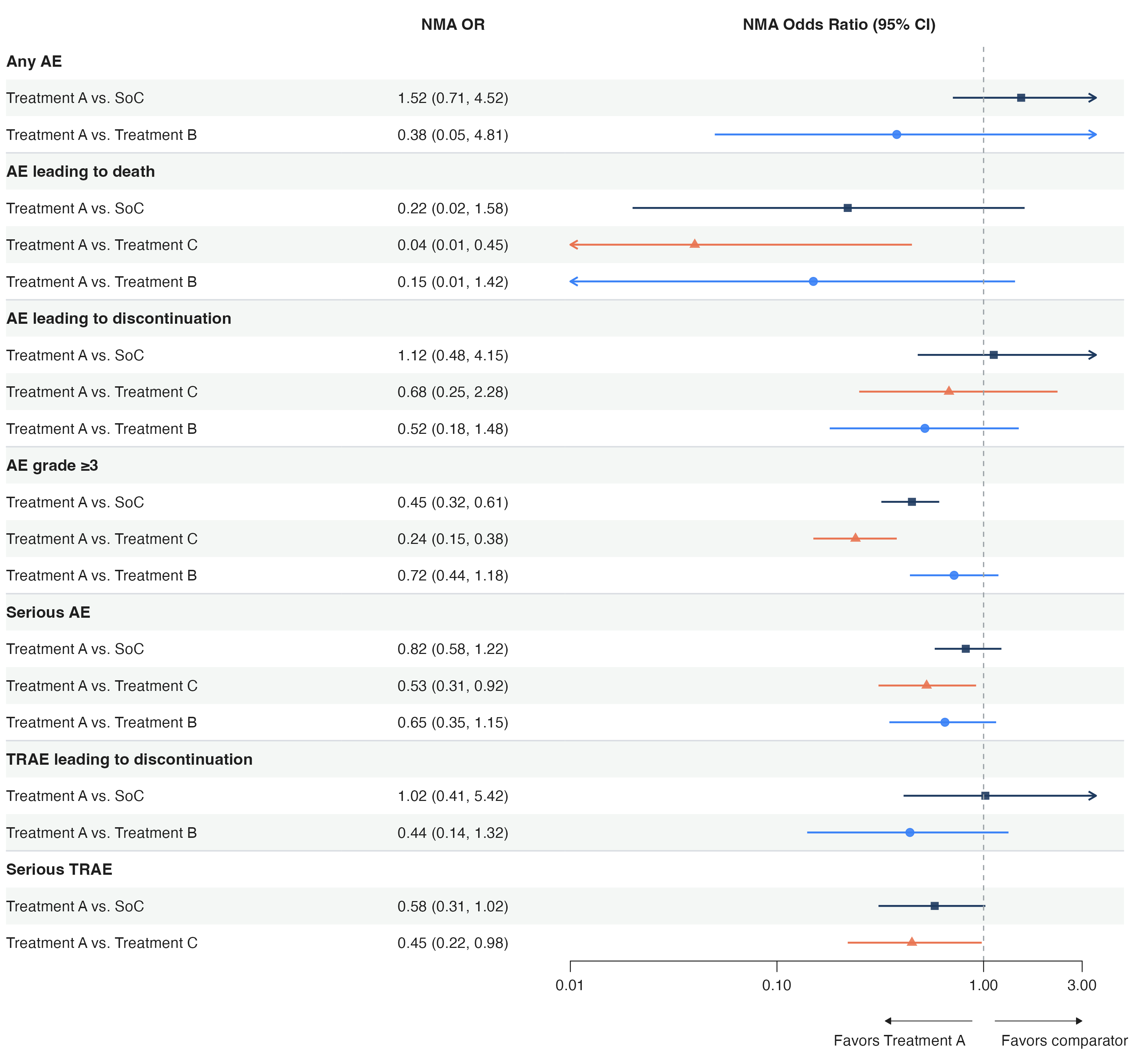
这张图是一个 NMA 安全性数据的森林图,包含:
- 左侧文本列(亚组标签)
- 中间文本列(OR 数值)
- 右侧 CI 面板(对数刻度、参考线、截断箭头、favors 标注)
- 分组行加粗、行间分隔线、条纹背景
- 不同比较用不同颜色和形状区分
生成这张图的代码大概 30 行,全部是管道式组合。
怎么用
基本结构
1 | library(panelforest) |
每个 add_*() 就是往布局里追加一列面板。顺序决定了从左到右的排列。想调整布局,移动调用顺序就行。
面板类型
目前内置了这些面板:
add_text()/fp_text()— 纯文本列,支持对齐、缩进、格式化函数add_text_ci()/fp_text_ci()— 把 est/lower/upper 三列自动格式化成 “0.45 (0.32, 0.61)”add_ci()/fp_ci()— 置信区间可视化,支持对数刻度、截断箭头、菱形汇总、favors 标注add_bar()/fp_bar()— 水平柱状图add_dot()/fp_dot()— 散点 + 误差线add_gap()/fp_gap()— 固定宽度间距add_spacer()/fp_spacer()— 绝对单位间距(mm)fp_custom()— 自定义面板,传入一个返回 ggplot 的函数
不够用的时候,fp_custom() 加上 fp_register() 可以注册自定义面板类型,引擎会自动纳入渲染流程。
列驱动的美学映射
跟 ggplot2 的 aes() 思路类似,panelforest 用 fp_aes() 把数据列映射到视觉属性:
1 | # 数据里有 ci_colour 和 ci_shape 两列 |
这样每一行可以有不同的颜色和形状,不需要手动逐行设置。
统一的 edit() 编辑层
想给某些行做特殊处理?一个 edit() 函数搞定行级、单元格级、行高调整:
1 | forest_plot(df) |> |
panel 参数可以用索引、标题字符串或列名来定位,不需要记面板编号。
跨列分组标题
多个面板可以用 add_header_group() 加父级标题,层级自动推断:
1 | forest_plot(df) |> |
支持多层嵌套——包含其他分组的分组会自动升至更高层。
设计上的一些取舍
为什么基于 ggplot2 + patchwork
每个面板本质上是一个独立的 ggplot 对象,最终用 patchwork 横向拼接。这个选择有几个好处:
- 继承 ggplot2 的渲染质量和主题系统
- 每个面板的坐标系独立,CI 面板可以用对数刻度,文本面板用 [0, 1] 坐标,互不干扰
- patchwork 的布局系统天然支持比例宽度和固定宽度混合
- 输出是标准 ggplot 对象,
ggsave()直接用
缺点是性能——面板多、行数多的时候渲染会慢。但森林图通常几十行到一两百行,这个量级下完全没有问题。
为什么不做 ggplot2 的 geom
另一条路是写 geom_forest() 这样的扩展。我没走这条路,因为森林图的本质是”多列异构面板”,每列的坐标系和渲染逻辑完全不同。硬塞进一个 ggplot 的 facet 或者 annotation 系统里会很别扭。
patchwork 的多面板方案更自然——每列是独立的 ggplot,互不干扰但共享行坐标。
fp_size() 的存在意义
森林图的尺寸应该由内容决定,不应该让用户猜 width 和 height。fp_size() 根据面板数量、行数和行高自动计算出精确的英寸尺寸:
1 | size <- fp_size(plot_obj) |
这样不管你加几列面板、数据有多少行,出图的密度和比例都是一致的。
CI 面板的细节
fp_ci() 是功能最密集的面板,支持的东西比较多:
- 对数刻度:
trans = "log",自动处理正值约束和刻度标签 - 截断箭头:CI 超出显示范围时,用箭头提示截断方向,箭头类型可配置 (
arrow_type = "open"/"closed") - 菱形汇总:
add_summary()标记的行自动渲染为菱形 - favors 标注:
favors_left/favors_right在坐标轴下方画方向箭头和标签 - 参考线:
ref_line画虚线 - 美学映射:通过
fp_aes()让每行有不同的颜色、形状、大小
这些功能单独看都不复杂,但组合起来就能覆盖绝大多数临床研究的森林图需求。
一个完整例子
1 | library(panelforest) |
从数据到出图,代码结构很清晰:数据 → 装饰 → 面板 → 渲染。想调整布局就移动 add_*() 的顺序,想改样式就加 edit()。
后续计划
panelforest 目前是 v0.2.0,核心功能已经稳定。后续打算做的事情:
forest_plot_from()— 模型直出森林图:传入glm、coxph、lm等模型对象,自动生成森林图。底层基于broom::tidy(),根据模型类型自动推断效应量(OR/HR/β)和坐标变换。逐步适配lme4、metafor、brms等更多包。add_rule()— 条件样式:声明式规则批量高亮,替代逐行edit()- 更多坐标变换:
sqrt、logit等 - 文本自动换行、导出助手、脚注系统等体验优化
最重要的是模型直出这个方向——让 panelforest 不只是一个画图工具,而是能直接对接统计建模的输出,减少”跑完模型还要手动整理数据再画图”这个环节。