 为什么写 PyKMExtract
为什么写 PyKMExtract
上一篇介绍了 PyHEOR,其中「文献 KM 图 → IPD → 参数拟合 → 建模」是一个很实用的流程。但实际操作中,第一步「从 KM 图提取坐标」仍然是手工活——要么用 WebPlotDigitizer 一个点一个点地点,要么用 Engauge Digitizer 半自动描线,一张双臂 KM 图搞下来十几二十分钟是常事。
当一个系统评价涉及十几篇文献、每篇两三张 KM 图时,手工数字化就变成了一件非常痛苦的事情。
所以我写了 PyKMExtract——一个面向研究场景的 KM 曲线自动化数字化工具。它从论文截图中提取结构化的 time / survival 数据,做基础验证,再桥接到 PyHEOR 做 Guyot 重建和后续生存建模。
项目地址:https://github.com/lenardar/PyKMExtract
核心设计:简单默认链 + 可选 AI 增强
这个项目的核心原则是:
默认提取链保持可解释、可复核;AI 可以参与,但只作为显式增强层,而不是整个测量过程的唯一来源。
为什么不直接让 GPT-4o 看一眼图就把坐标吐出来?因为 LLM 的视觉能力擅长理解「这张图画了什么」,但不擅长做「这个像素在第几行第几列」这种精确测量。把语义理解和精确测量混在一起,出了错很难定位。
所以 PyKMExtract 的默认流程是这样分层的:
1 | 语义提取 → 坐标轴检测 → 颜色提取 → KM 阶梯采样 → 坐标映射 → 验证 |
AI 负责语义,像素测量交给确定性算法。 两层各自可验证,出了问题一眼就能看出是哪个环节。
提取流程拆解
第一步:语义提取
「语义」是指图中的结构化信息:有几条曲线、每条线叫什么名字是什么颜色、坐标轴范围是多少、有没有 number-at-risk 表。
支持两种来源:
- 手动准备
semantic.json:适合高精度场景,坐标轴范围和颜色人眼确认 - 在线视觉模型:接任何 OpenAI 兼容接口(GPT-4o、Qwen-VL 等),自动识别
视觉模型的调用通过结构化 prompt 引导,要求严格按 JSON schema 输出,并做自动重试和归一化。模型返回的 rgb_approx 只是近似值,后面的颜色提取会用自适应容差去修正。
第二步:坐标轴检测
自动检测图中的坐标轴线位置,得到绘图区域的像素边界。
算法很直接:对灰度图逐行逐列扫描,找最长的连续深色像素段,水平线和垂直线交叉的位置就是绘图区原点。如果两条轴线的检测结果不太对(比如图上没有明显轴线),会退回到非白色区域的包围盒。
这一步还支持可选的 AI 四点校轴:用视觉模型在图上标注候选锚点,模型选择并微调,得到更精确的四点映射。这对坐标轴不完全正交、或者图中有裁切偏移的情况很有用。
第三步:颜色提取
知道了每条曲线的大致 RGB 颜色后,用欧氏距离在绘图区内找匹配像素:
1 | distance = sqrt((R - R_target)² + (G - G_target)² + (B - B_target)²) |
容差不是固定的——自适应容差扫描从紧(tolerance=8)开始逐步放宽(8→12→18→24→32→…),直到像素数量和 x 方向覆盖度都满足要求为止。这样既不会因为容差太紧漏掉像素,也不会因为太松把背景噪声混进来。
如果图上有置信区间色带(CI band),会通过列密度统计自动去除——色带在每列的像素密度远高于曲线本身。
第四步:KM 阶梯采样
这一步是 PyKMExtract 和通用曲线数字化工具的关键区别。
KM 曲线是右连续阶梯函数——水平段表示没有事件发生,垂直跳降表示事件。普通的曲线采样用中位数或均值,但这会把垂直跳降平滑掉,丢失 KM 的阶梯特征。
PyKMExtract 的做法是:每列取下包络(最大 y 像素值,即最低点),然后用右连续前向填充重采样。这样水平段保持水平,垂直跳降保持为瞬间跳变,不会产生虚假的斜坡。
1 | 原始像素云 → 逐列下包络 → 规则 x 网格重采样 → 阶梯曲线 |
第五步:坐标映射与清洗
像素坐标通过四点锚定线性映射到数据空间(time, survival)。如果 y 轴是百分比(0–100),自动归一化到 0–1。
清洗步骤包括:
- 按时间排序、去重
- 抑制孤立的下降毛刺(短暂下跳后立即回弹的噪声)
- 折叠短下降段(粗线条边缘造成的虚假斜坡)
- 强制累积最小值(保证单调非递增)
- 如果首个时间点不是 0,自动补
(0, 1.0)原点
第六步:验证
提取完成后不是直接输出,而是先做一组验证检查:
| 检查项 | 权重 | 说明 |
|---|---|---|
| 单调性 | 30 | 生存概率必须单调非递增 |
| 范围 | 20 | 所有值必须在 [0, 1] 内 |
| 起点 | 15 | 第一个点应接近 1.0 |
| 覆盖率 | 15 | 曲线应覆盖至少 75% 的 x 轴范围 |
| at-risk 一致性 | 20 | 提取的生存概率与 number-at-risk 表隐含的比例不应偏差过大 |
加权后得到 0–100 分。还会额外检测重叠歧义——如果两条曲线有长段像素重合,分数会被压到 medium,提示需要人工复核。
验证不是为了掩盖问题,而是为了把问题暴露出来。难图应作为低置信结果保留,而不是强行伪装成高分。
实际用法
单图提取(已有 semantic JSON)
1 | pykmextract figure.png \ |
单图提取(在线视觉模型)
1 | export OPENROUTER_API_KEY="..." |
开启 AI 校轴
加上 --axis-refine,会多跑一次视觉模型来校正四个轴锚点:
1 | pykmextract figure.png \ |
Python API
1 | import pykmextract as pkm |
批处理
当你有一批文献的 KM 图需要处理时,把图片按 study01_os.png / study01_pfs.png 这样的命名放到一个目录,然后:
1 | # 生成 manifest |
输出按 study 和 endpoint 组织:runs/study01/os/、runs/study01/pfs/…
输出内容
每个提取任务输出一个 review bundle,供人工复核:
original.png— 原图备份overlay.png— 提取曲线叠加在原图上的对比图digitized_curves.csv— 提取的数值坐标review.md— 结构化 review 报告reconstructed_km.png— 从重建 IPD 重绘的 KM 曲线(当 PyHEOR 可用时)ipd_*.csv— 重建的个体数据
overlay 是最直观的验证方式——提取的虚线和原图实线重合程度如何,一目了然。
真实文献测试
我在 5 篇 JAMA Oncology / Lancet 的三期临床试验文献上做了测试(10 张 panel,涵盖 OS 和 PFS)。
10 张 panel 的 overlay 总览:
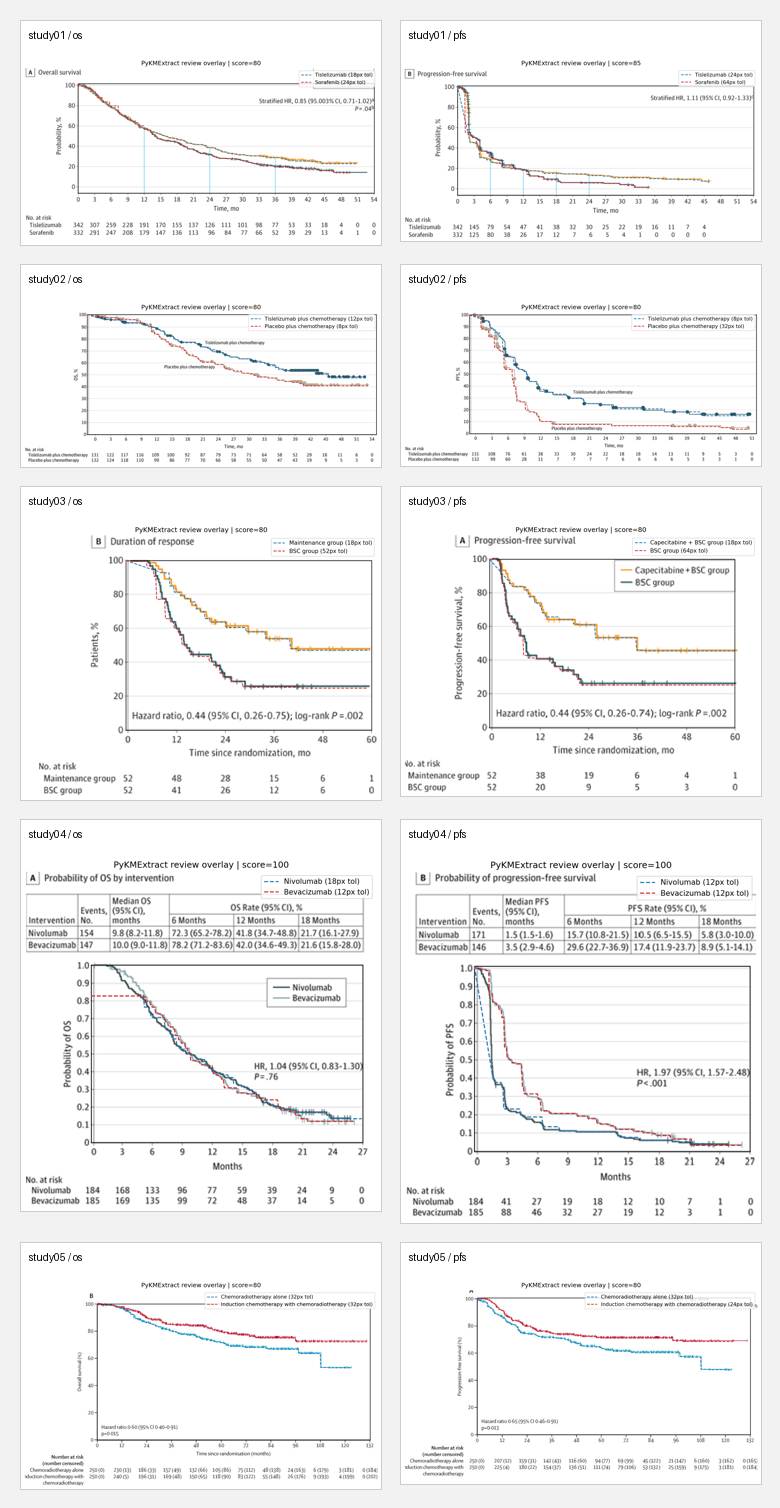
逐张人工复核后的评价:
| Panel | Score | 评价 | 主要问题 |
|---|---|---|---|
| study01 / os | 80 / high | 较好 | 尾部与 at-risk 有偏差 |
| study01 / pfs | 85 / high | 可用 | 后半段 coverage 不足 |
| study02 / os | 80 / high | 可用 | 两条线都与 at-risk 有偏离 |
| study02 / pfs | 80 / high | 偏弱 | 中后段偏低 |
| study03 / os | 80 / high | 偏弱 | 台阶较粗,at-risk 一致性弱 |
| study03 / pfs | 80 / high | 偏弱 | 后段像近似曲线 |
| study04 / os | 100 / high | 最好 | 与原图最接近 |
| study04 / pfs | 100 / medium | 较好 | 两条线长段重合,主动压分 |
| study05 / os | 80 / high | 较好 | 主要扣分来自 at-risk |
| study05 / pfs | 80 / high | 较好 | 同上 |
效果最好的一张(study04 / os,CheckMate 143):
原图 vs 重建 KM 对比:
| 原图 | 从重建 IPD 重绘的 KM |
|---|---|
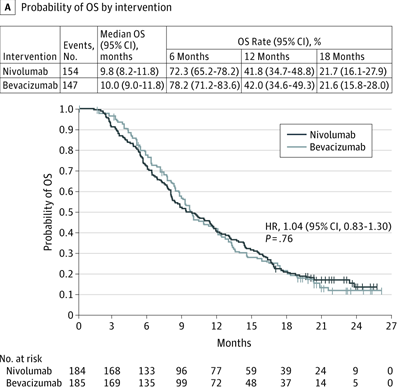 |
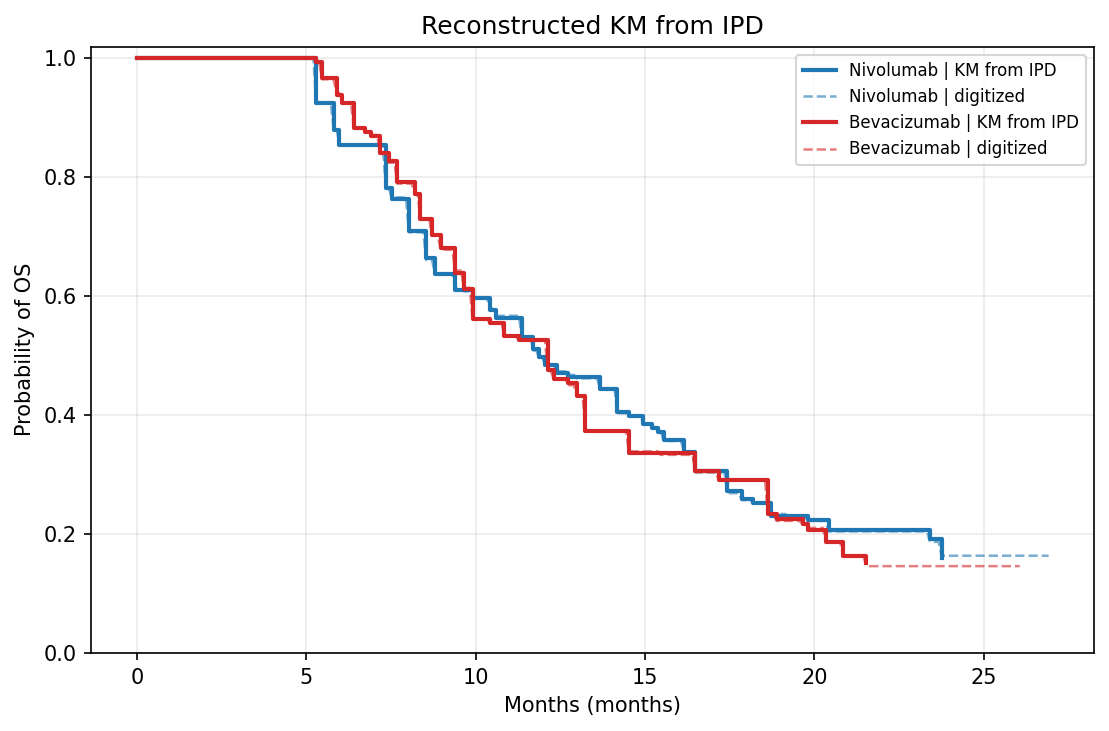 |
提取 overlay:
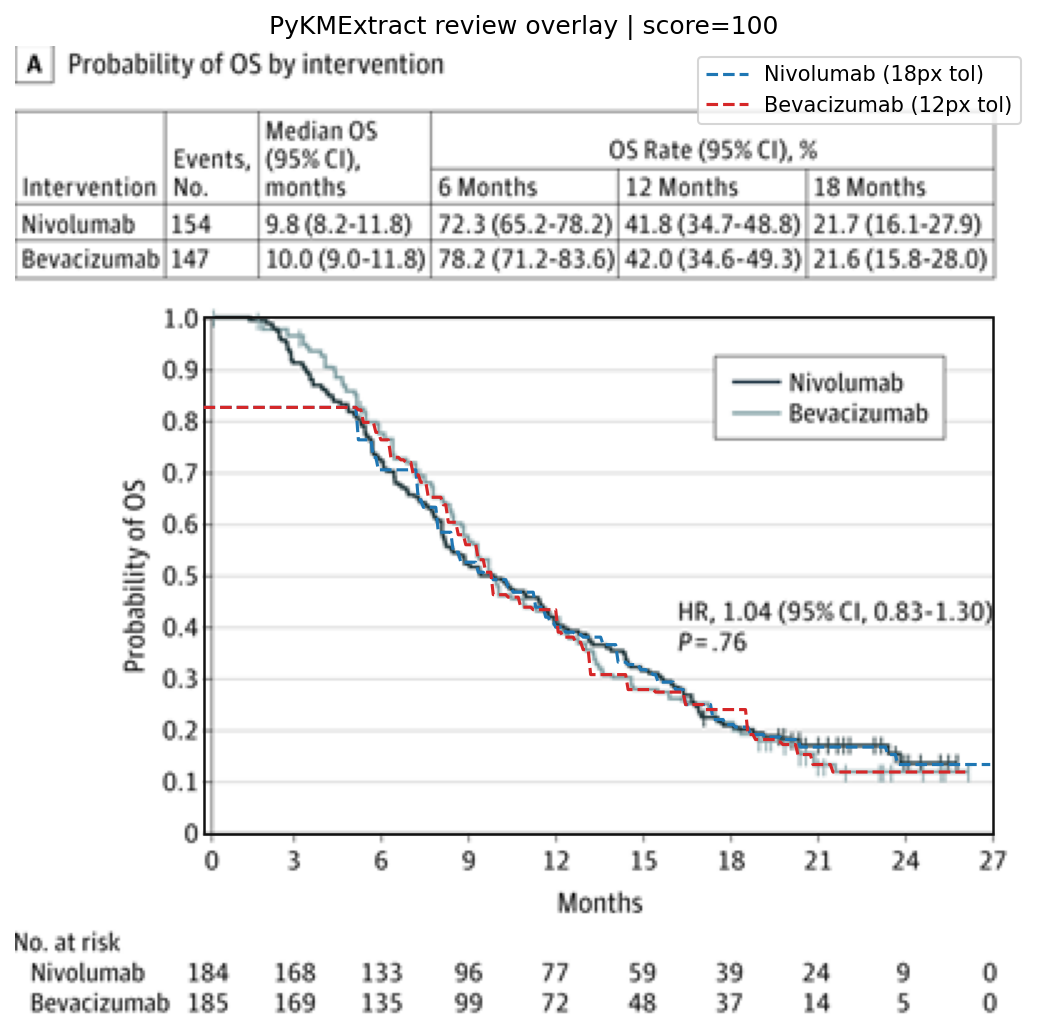
更客观的结论是:
- 在白底、高对比、1-2 条曲线的常见 KM 图上,PyKMExtract 基本可以做到「自动提取 + 人工快速复核」的工作流
- 当前仍然偏弱的场景:灰度图、颜色接近的多条线、密集置信区间带、低分辨率扫描件
- 分数不是目的,overlay 才是——80 分的图可能目视效果很好,100 分的图也可能因为重叠歧义被压到 medium
与 PyHEOR 的配合
PyKMExtract 的输出可以直接喂给 PyHEOR 做 Guyot 重建:
1 | import pykmextract as pkm |
这就实现了完整的「论文 KM 截图 → 自动提取 → IPD 重建 → 参数拟合 → 经济学建模」流程,中间的手工数字化环节被自动化了。
已知限制
当前仓库是一个实用型 MVP,不是「所有 KM 图都能稳提」的通用数字化器。明确不太行的场景:
- 灰度图或颜色接近的曲线(颜色提取依赖 RGB 距离)
- 多条线密集重叠的图(重叠段无法仅靠颜色区分)
- 明显置信区间带和密集删失标记(CI 去除是启发式的)
- 低分辨率扫描图或重度压缩截图
- 全自动 PDF 拆页
这些限制是有意识的取舍——与其用不可靠的魔法把难图包装成高分结果,不如诚实地报一个低分,留给人工处理。
后续计划
- 更好的边界案例处理(灰度图、低对比度)
- 更智能的重叠曲线分离策略
- 支持更多视觉模型后端
- PDF 直接输入(自动识别 KM 图所在页面)
- 与 PyHEOR 的更深度集成(端到端 pipeline)
如果你也在做系统评价或者卫生经济学建模,需要从文献中提取 KM 数据,欢迎试用和反馈:PyKMExtract on GitHub